

![[DIY] Scraping Tables From A PDF](https://cdn.hashnode.com/res/hashnode/image/stock/unsplash/D9Zow2REm8U/upload/820620df8398fbff0a695b90d91ff3f4.jpeg?w=1600&h=840&fit=crop&crop=entropy&auto=compress,format&format=webp)

Photo by Hitesh Choudhary on Unsplash
[DIY] Scraping Tables From A PDF
Scraping a website is easy, but have you ever wondered how one can scrape PDFs? Especially tables? Here's what I learned and discovered.


Recently I had a problem, scraping the forex card rates from a PDF published by SBI on their website and converting the same to a CSV file. This PDF is updated on the same link every day.
As quoted by the final source where I got the code from -
Explanation to Rule 26 of the Income Tax Rules, 1962 advises using telegraphic transfer rates of SBI as reference for calculating foreign income or capital gains. SBI publishes the rates daily on its website, barring Sundays and bank holidays. Unfortunately, there is no official way to access historical data.
The Challenge
Scraping a PDF normally is easy, considering that there are already many open-source projects available for the same. But here, this PDF had data present in tables as shown below -
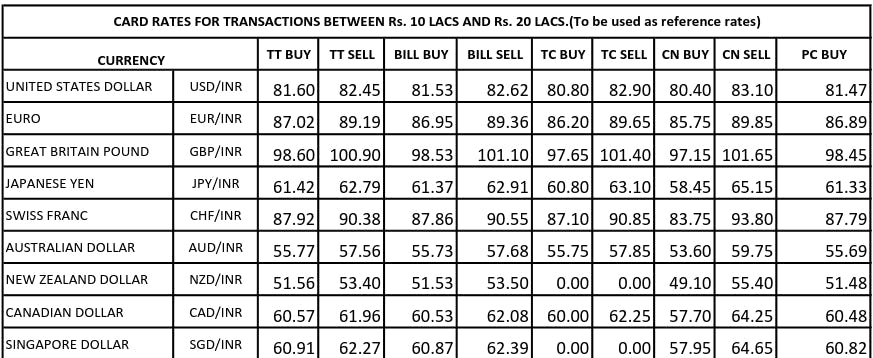
My Approach
Before I found the complete solution to my problem readymade (scroll directly below if you want to skip this), I had made up my mind to build the entire scraper using Node.
I came across many NPM packages to help me with the same, but almost none of them had a built-in approach for parsing tables in a PDF. I struck a gold mine by finally finding an NPM package - pomgui/pdf-tables-parser.
It was the exact solution I was looking for, except, as of 10th January 2023 an update to one of its dependencies pdfjs-dist, the generic build of pdfjs caused the package to break.
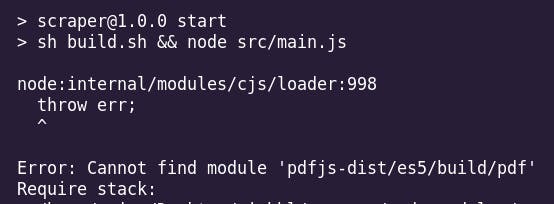
The Fix
I would be lying if I said that I fixed the issue in minutes. At first, I thought it was some issue with the node_modules I downloaded and spent some time installing the dependencies I was shown was missing. Only after some time when I went through the source code of the pdf-tables-parser, did I realize the path for the build of pdfjs-dist had changed from pdfjs-dist/es5/build/pdf to pdfjs-dist/build/pdf.
A quick fix and update to that had fixed the missing dependencies errors. I put in a pull request on the GitHub repository of the package.
The Code
Downloading the PDF from the website - Using the
async awaitwill ensure we can wait for the download asynchronously. The npm packagedownloaduses a function to pass in the URL and the output folder path.const download = require('download'); async function fileDownload() { // download(link, output folder) await download('https://www.sbi.co.in/documents/16012/1400784/FOREX_CARD_RATES.pdf', 'input'); }Converting the acquired PDF to JSON - This was made easy after using the pdf-tables-parser package.
The code below gets the downloaded PDF from the input folder, extracts the data, and writes it to a
report.jsonfile in theoutdirectory.const { PdfDocument } = require('@pomgui/pdf-tables-parser'); const fs = require('fs'); async function PDFToJSON() { const pdf = new PdfDocument(); // pdf.load('path/to/PDF') await pdf.load('input/FOREX_CARD_RATES.pdf') .then(() => fs.writeFileSync('out/report.json', JSON.stringify(pdf, null, 2), 'utf8')) .catch((err) => console.error(err)); }Here are the dependencies in the
package.jsonfor reference -"dependencies": { "@pomgui/pdf-tables-parser": "^0.1.0", "download": "^8.0.0", "path": "^0.12.7", "pdfjs": "^2.4.7", "pdfjs-dist": "^3.2.146" }The Issue
This code was inefficient as the JSON was not uniform. No doubt that all the contents of the PDF are scraped but it is too ugly and variable to look at.
Here is how the JSON looked
{ "tableNumber": 7, "numrows": 1, "numcols": 1, "data": [ [ "UNITED STATES DOLLAR USD/INR " ] ] }, { "tableNumber": 8, "numrows": 2, "numcols": 9, "data": [ [ "81.25", " 82.75", " 81.18", " 82.92", " 80.5", " 83.2", " 80.2", " 83.4", " 81.12" ], [ "EURO EUR/INR " ] ] },The Python Fix
This amazing GitHub repository solved my entire issue of scraping the said PDF - https://github.com/sahilgupta/sbi_forex_rates
Thanks to Sahil's solution the task of scraping had been achieved, leaving me with modifying the existing code to scrape page 1 and upload it to Amazon S3 Bucket.
Connecting to the S3 bucket
import os import boto3 from dotenv import load_dotenv load_dotenv() s3 = boto3.client( "s3", aws_access_key_id=os.getenv("aws_access_key_id"), aws_secret_access_key=os.getenv("aws_secret_access_key"), )Uploading the CSV files
import pandas as pd def upload_csv(): # This loop ensures that all the files and folders in the # directory "csv_files" is uploaded for path, subdirs, files in os.walk("csv_files"): for name in files: hc = pd.read_csv(os.path.join(path, name)) csv_buf = StringIO() hc.to_csv(csv_buf, header=True, index=False) csv_buf.seek(0) s3.put_object( Bucket=os.getenv("bucket_name"), Body=csv_buf.getvalue(), Key=os.path.join(path, name), ) print("Uploaded CSV to bucket")Uploading the PDF files
# This loop ensures that all the files and folders in the # directory "pdf_files" is uploaded for path, subdirs, files in os.walk("pdf_files"): for name in files: s3.put_object( Bucket=os.getenv("bucket_name"), Body=os.path.join(path, name), Key=os.path.join(path, name), ) print("Uploaded PDF to bucket")Scraping Page 1 - This is simple, since both the pages are the same all you need is to start from the second index for the table headers and start at the 3rd index for getting the values. Hence, the changes to be made to the
dump_datafunction in the source code will be -header_row = lines[2]and
for line in lines[3:]:
Concluding Notes
Scraping using Python was an easier task compared with NodeJs. Maybe my approach was wrong when scraping with Node but I felt that scraping with Python felt cleaner and the work got done faster.
You can now schedule a cron job to run the main function/ file to scrape the SBI Forex website. If a change is detected, it will automatically update the CSV.